Unsupervised Musical Timbre Transfer for Notification Sounds
Jing Yang, Tristan Cinquin, Gábor Sörös
We train a neural network to transform artificial notification sounds into different musical timbres. In addition, we envision notification timbre transfer as a way for less distracting information delivery by embedding a timbre-transformed notificaion into the music piece that a user is listening to.
Our notification timbre transfer network is based on the CycleGAN structure, trained with unpaired samples. For the source domain, to tackle the issues of ambiguous timbre definition and insufficient training data of notification sounds, we use video game music that shares similar timbral features with notification sounds. The video game music was collected from the following YouTube sites: video game music 1, video game music 2, video game music 3, video game music 4, video game music 5, video game music 6.
For the target domain, we collect music of different instrument timbres from the MusicNet dataset and YouTube:
- Piano: MusicNet
- Cello: MusicNet
- Guitar: Best of Bach - Classical Guitar Compilation - BWV
- Piano-accompanied violin: MusicNet
- Orchestra instruments (string, woodwind, brass, percussion sections, etc.): The Best of Classical Music
The source codes for (1) training the notification timbre transfer model and (2) objective evaluations of melody preservation can be found in the github repo.
Part I: Notification timbre transfer to single-instrument timbre
| original | piano | cello | guitar | |
|---|---|---|---|---|
| Notification 1 | ||||
| Notification 2 | ||||
| Notification 3 | ||||
| Notification 4 | ||||
| Notification 5 | ||||
| Notification 6 |
Part II: Notification timbre transfer to multi-instrument timbre
Compared to the transfer to a single-instrument timbre, when a model is trained for a multi-instrument timbre, it is difficult to map a monophonic notification to a homophonic or even polyphonic music piece with several timbre tracks. The original melody envelope of the notification can still be kept to a good extent, but the output notifications often have an unnatural mixed timbre of the instruments in the target style.
We show examples for two target multi-instrument timbres: (1) piano-accompanied violin, (2) orchestra instruments. We first show a sample music for each of these two styles.
| piano-accompanied violin | orchestra instruments |
|---|---|
In the following, we show notification samples that are transferred to these two multi-instrument timbres
| original | piano-accompanied violin | orchestra instruments | |
|---|---|---|---|
| Notification 1 | |||
| Notification 2 | |||
| Notification 3 | |||
| Notification 4 |
Part III: Less distracting information delivery with notification timbre transfer
A potential application of notification timbre transfer might be less distracting information delivery. Notifications cause stress and distraction which can affect people's task performance, but disabling them is not a satisfying solution for most users because they will become unaware of their activity context. Since digital music has been widespread, researchers have explored to deliver notifications in a less pronounced way by modifying the music that a user is listening to.
The concept of embedding notification into music might also be achieved with the notification timbre transfer technique. We could first change the timbre of the notification to match the music being played, then embed the timbre-transferred notification into the music track, and so deliver notifications in a less intrusive manner.
We present music examples to demonstrate this concept.
| original piano music | original notification | notification in piano timbre | piano music integrated with notification (at 5s) |
|---|---|---|---|
Part IV: Comparison between the models trained using video game music and electronic music
In addition to the video game music, we have also explored the performance of the model trained using electronic music as the source data, since we assumed timbral similarity between the electronic music and the notification sounds. The electronic music was collected from the GTZAN dataset. We found that using the electronic music, in general, led to less satisfying output notifications than using the video game music to train the timbre transfer model.
One reason could be related to the musical timbre. By visualizing the VGGish feature vectors (see more explanation in Section 3.1 of our paper), we found that compared to the video game music, the musical timbre of the electronic music is overall less similar to the notification sounds. The following figures highlight the comparison in the dark blue rectangle frames.
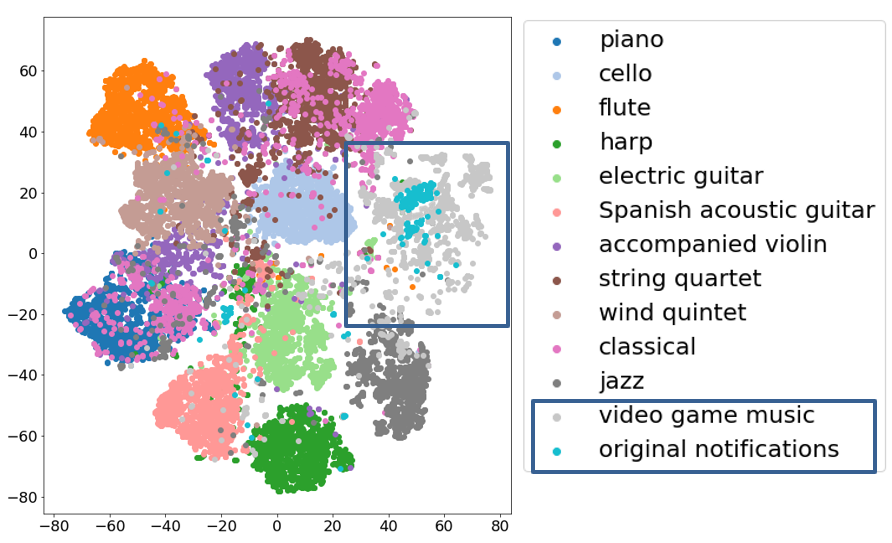
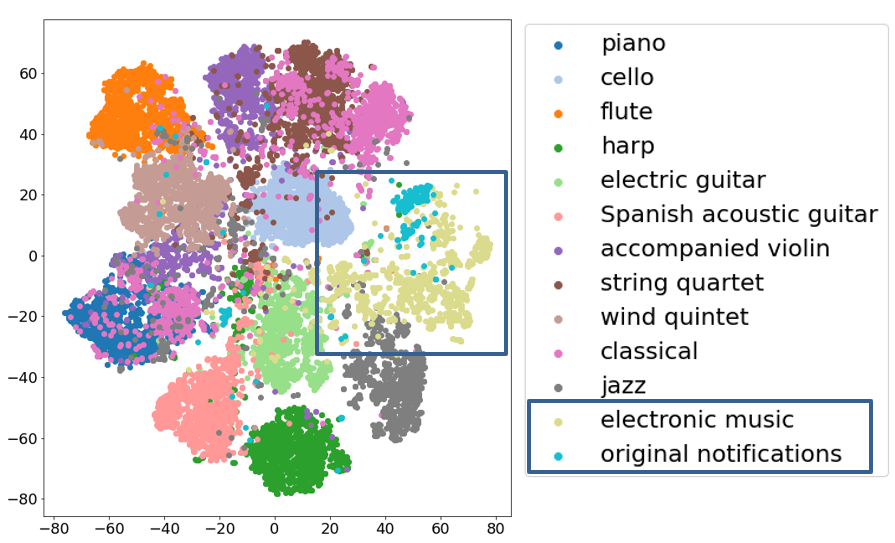
Note: it is normal that the VGGish feature vector clusters in the above figures look not exactly the same as those in Fig.2 of our paper, due to, e.g. the re-initialization of the t-SNE algorithm for embedding and plotting. However, the overall pattern of the clustering, which represents the overall timbral similarities and dissimilarities, stays stable.
You can listen to the following audio samples to experience the perception difference between the models trained using the video game music and using the electronic music, respectively.
| original | piano (trained with the video game music) | piano (trained with the electronic music) | |
|---|---|---|---|
| Notification 1 | |||
| Notification 2 | |||
| Notification 3 | |||
| Notification 4 | |||
| Notification 5 | |||
| Notification 6 | |||
| Notification 7 | |||
| Notification 8 |